Modernize R&D Data Lake by extending it to the Cloud
The market is moving towards a hybrid approach to data management. The organizations are trying to solve complex problems with a mix of alternative and traditional deployments. The design of previous data lakes can't satisfy current demands for speed, flexibility, innovation, and scalability.
Data is infused in all aspects of R&D. It fundamentally transforms how the pharmaceutical industry discovers and develops medicines for patients. To do so, R&D had to rely on the ability to rapidly store and process huge volumes of data in real-time from different sources and also in different formats to build a future-facing, agile R&D organization that will drive increased and sustainable levels of product innovation.
 Growing demand in Pharma R&D to develop insights on increasingly diverse data sets is a challenge.
Growing demand in Pharma R&D to develop insights on increasingly diverse data sets is a challenge.The Challenge
Big data’s variety, volume, and velocity cannot be served well with legacy model-map-move approaches and requires highly automated integration and data provisioning capabilities for a combine, relate, ingest, persist, and access. On-premises data lakes are meant to be extremely adaptable and adjustable options for resolving difficult queries by combining all accessible data sources. With the introduction of a data lake approach, providers and health plans are striving to enrich their data to forecast risk or higher costs patterns utilizing a larger data set. With the addition of values, these new predictive metrics can demonstrate a higher degree of relevance.
The top minds in the world now have access to vast amounts of data; an ocean of information from which they draw up patterns that could potentially lead to generating high-value biological insights and validated targets, reduce cycle time, improve quality, save time, and costs in clinical trials.
However, to extract meaningful correlations from data patterns, we must embrace all of today's supercomputers' number-crunching capacity as well as the rapidly evolving area of Big Data. These new technologies enable us to ask questions about cancer in ways that were simply not possible before.
In clinical trials, gene sequencing typically requires the sequencing of hundreds of millions of pieces, and hundreds of these tests have to be performed to make an observation that can be a candidate for a pattern. That is the scale of data that we must embrace, and this is where the challenge comes in.
With the massive amount of clinical and research data, which is growing rapidly, on-prem data lakes are facing challenges which data lakes run on Big Data Platforms with requiring an abundant amount of maintenance, scaling, capacity planning.
Complex IT Ops in RDDL
RDDL is growing very quickly, and they needed a platform that could carry them into the future. As most of the data is consumed by downstream applications monolithic environment that used a parallel queuing architecture and could only handle a few reports at a time. These workloads vary greatly, ranging from a few thousand tests per hour during off-peak to 10,000 or more per hour on the peak. In the on-prem environment, we have provisioned for maximum capacity and keep servers running at all times.
Companies are slowing themselves down. They are reverting to tried-and-true ways for upgrading technological architectures, such as holding off on developing a data-lake solution until they have one that is exactly perfect, and participating in long, drawn-out internal conversations about ideal designs, products, and suppliers. Companies who do so will be able to keep up with quickly changing data regulatory and compliance norms.
Challenge 1 – Scaling and Maintenance
On-prem infrastructure runs 10,000+ queries/day, 30+ applications, 2000+ users, 160 TB of data, and 3500 Studies and processes, a huge amount of data that is consumed by different downstream applications. Many jobs are scheduled and run daily. As data is growing rapidly, more business functional areas would like to use R&D Data Lake to keep their data. Many downstream applications connect to the data lake and consume data.
We deal with almost every aspect of data management, including data collection, storage, processing, and analysis. Certain changes may be implemented while keeping the core technology intact, but they need careful re-architecting of current data platform and on premise infrastructure, which includes both heritage and newly bolted-on technologies.
Challenge 2 – Slow De-Identification Process in IDAR
IDAR images from DICOM (International standard to transmit, store, retrieve, print, process, and display medical imaging information) and Halo Link currently take days to anonymize terabytes of an image file.
Problem Statement:
- High volume of image files in terms of the number of sizes takes a long time to de-identify the image files (a few days to process 20TB of Data).
- Too much manual intervention in the flow adds up to the overall time (manually images are extracted from Halo).
- Too many hops also adds up to the overall time.
The Solution
Simplified and efficient IT ops
Establish a common data platform to seamlessly collect, integrate, analyze and share data across R&D. Inform discovery and TA teams by combining historical and real-time research data with clinical insights and real-world data at every step of the R&D process.
R&D Data Lake on cloud offers the following advantages as compared to on premise R&D Data Lake.
- Server reduction - Smaller global footprint, server on-demand, best-in-class infrastructure.
- Automated IT - Standardized architecture and data center.
We can achieve incredible data ingestion, processing, and query performance, while we don’t have to invest capital to do it. Integrating a container on a cloud-based data platform, with a huge amount of data to make transferable applications and capabilities.
Slow de-identification process in IDAR
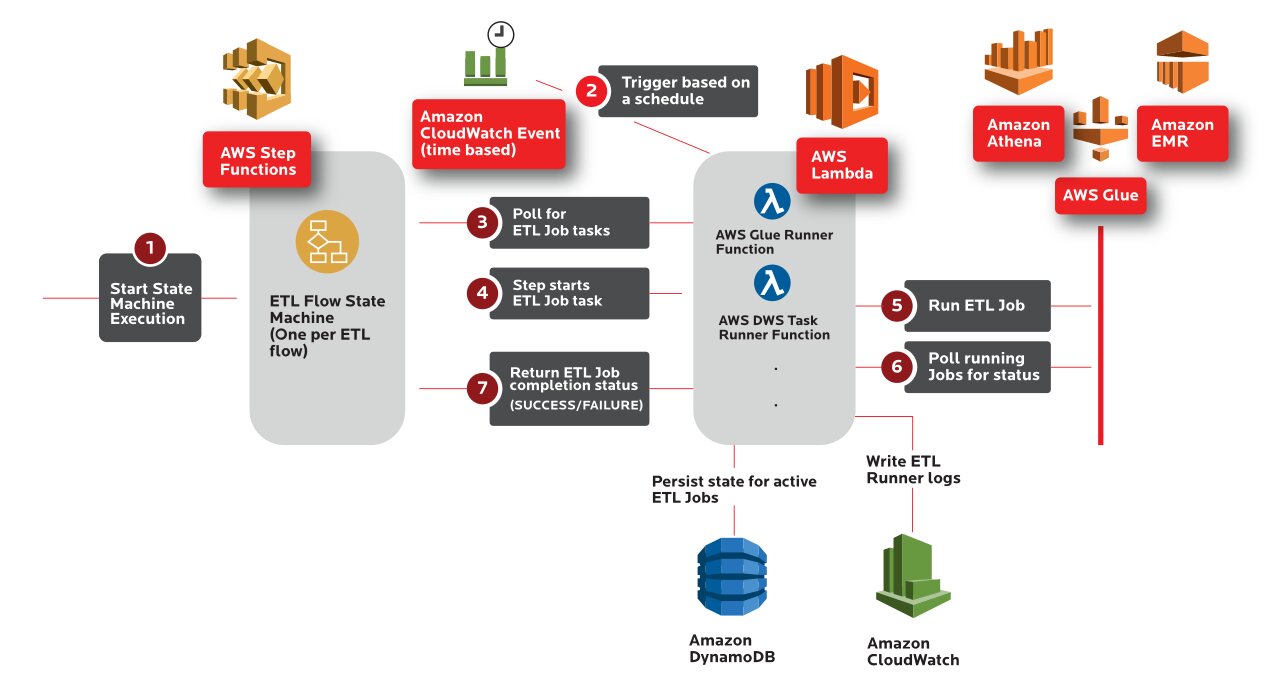
Once a folder with image files is copied, a lambda function is triggered that invokes the lambda anonymization job. One lambda function will process one image file in 10-15 seconds. AWS Glue script replicates the manual extraction tool steps in python script based on storage information.
AWS services like Glue, Lambda, IAM, S3, Dynamo DB, CloudWatch, Athena, EMR, etc. are used.

The Impact
VPCx big data simplified architecture patterns
Leverage the AWS VPC platform's scalable, elastic framework to handle structured and unstructured data as well as large data streams with the ability to deploy fast and at a low cost, and get to insights quickly with less provisioning in a rapid fashion.
- Data rich applications with next to infinite scale without the inconvenience of installing, configuring and managing workloads can be built and operated using serverless data platforms. Such services can reduce the amount of knowledge required, reduce deployment time from weeks to hours, and require almost no operating on-costs.
- The containerized data solution was implemented using Kubernetes. This was done to facilitate the data platforms with difficult configurations. For example, some applications needed to hold the data from one session to another and hence required complex recovery and data backup solution. Which in turn needed extra compute power and quick storage systems. This was enabled using Kubernetes.


{kind=link}